
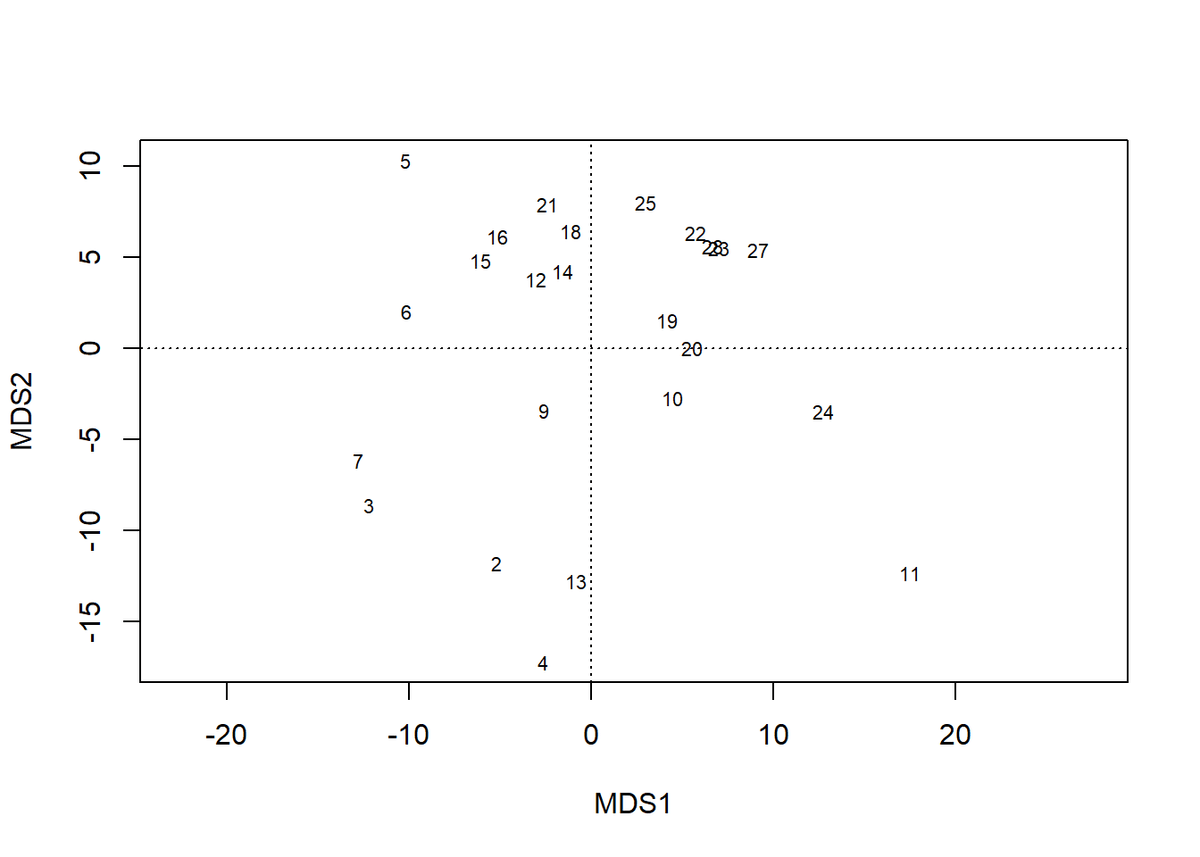
Looking a the 'original' data points (blue dots) it is quite obvious that dimensions 1 and 2 are not independent and that neither of them is ideally suited for describing the data. Let's look at a simple 2D plot to understand what that means A basic technique well-suited for this problem is the Principal Component Analysis which tries to find the directions of most variation in your data set.

One approach is to reduce the dimensionality of the feature space and poke around in this reduced feature space. In this case exploratory data analysis (EDA) is challenging and we need to resort to alternative methods of visualizing and exploring the feature space. states leads already to 50 variables fn-independence. Alternatively, data source can be so rich that already the raw extraction produces a vast amount of data, e.g. as features, which quickly becomes very large. To give an example: In a timeseries problem, one could use cumulative sums, moving averages with variable window sizes, discrete state changes, average differences, etc. What I mean by that is that we extract and engineer all the features possible for a given problem. A typical approach in Data Science is what I call featurization of the Universe.